Stream Compaction
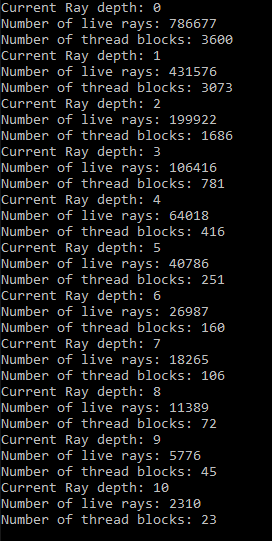
The current rendering implementation works as follows. Each time the display function of OpenGL is called, the renderer calls its Render function. This launches a series of kernels on the GPU. First, we initialize the quantities we need. We keep track of the number of pixels whose rays have not yet been terminated, and an array of indices corresponding to the live pixels is kept in order to know which rays correspond to each pixel. We then shoot rays from the camera and in an iterative manner trace them in parallel through the scene as they bounce. When an array is terminated, ie. it either misses the scene components or it’s potential color contribution falls below a certain threshold, the ray index for that pixel is set to -1. This way, in each bounce iteration we can compact away and remove the rays that have terminated in the last iteration. This is done by passing a predicate to a function of the thrust-library dictating wether the value is negative or not. Doing this comes with a slight overhead that can cause a reduction in rendering efficiency for scenes where most rays are alive for a long time (closed scenes). In open scenes however, many rays terminate early and we can then increase the occupancy on the GPU by reducing the amount of idle threads in each warp. Instead of waiting until all rays have terminated, we assign threads only to the rays that are still alive, reducing the total amount of CUDA thread blocks needed. Below is an image showing how the live rays are reduced after each iteration and how the number of blocks is reduced as well.
I have begun implementing triangle mesh loading, but for now it’s rather messy. I have changed all the math classes from the CUDA native classes such as float3 and uint2 to the corresponding functions from the glm library in order to get quicker access to some matrix classes. It seems like the native CUDA types are slightly faster so in the future I will ideally write my own matrix class for geometry and camera transformation.