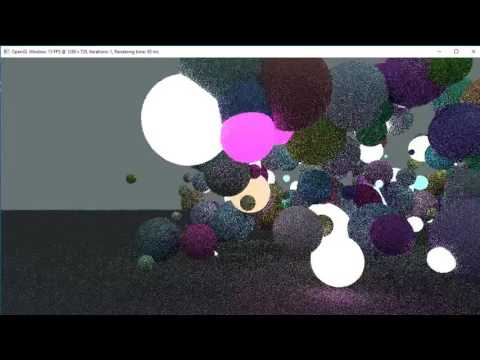
Now that we can average colors over frames, sample well-distributed random numbers and cast rays from the camera we can set up a simple scene to test an initial path tracing implementation. Before I manage implementing a more general triangle mesh loading and bounding volume hierarchy, I implemented a HSphere class with a position and radius and a HScene class that holds information about the current scene setup, which for now is nothing more than an array of spheres. The HSphere also has a HMaterial with Diffuse color and Emission values.
At each iteration in the renderer, rays are initiated from the camera in one CUDA kernel and are then traced as they bounce through the scene in an iterative way until they either terminate or reach a maximum ray bounce depth. For each ray depth, we trace the rays in another CUDA kernel which performs ray-sphere intersection tests with the scene and accumulates color. The rays are then given a new origin at the intersection point and a new direction sampled from a cosine weighted distribution in the hemisphere, so that each ray can be traced further from the intersection point. When the maximum ray depth is reached, we pass the accumulated colors for this iteration to the accumulation buffer which is then displayed.
The first implementation I did was not performing the hemisphere sampling correctly which led to incorrect lighting artefacts as can be seen in the pictures below.


After having corrected this, there were still some ring artefacts present arising from the fact that I was not offsetting the new ray locations after each bounce from the surface far enough, causing self-intersection. This should be handled properly in the future, either by passing the index of the object the ray is bouncing from in order to ignore it, or by some more thorough floating point error analysis.

After having adjusted the offset slightly, I can now render scenes containing diffuse spheres. Below is an example showing the depth of field effect, resulting from the aperture sampling in the ray initialization kernel.

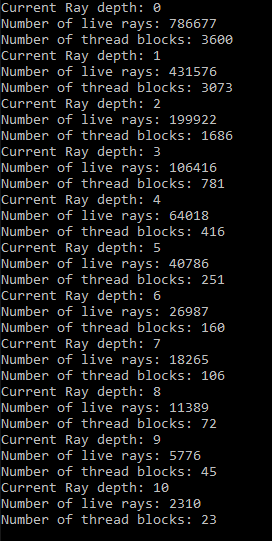
The next post will be about using stream compaction to remove threads responsible for terminated rays, allowing us to increase the occupancy and minimize the amount of threads that will be waiting for other threads in the same warp to finish executing.
The stream compaction feature along with a lot of other implementation details in this project was inspired by a similar project conducted by Peter Kutz and Karl Li back in 2012. Their work has been very inspirational and has motivated me to build my own rendering system to learn more about programming and light simulation. Their project is available on GitHub here. Another person who has been very helpful so far in the project is Sam Lapere, who has very kindly been answering all of my e-mails and explaining some intricacies of the implementations in the tutorials on his blog.